Workshop on "Objects of Interest and Necessity"
For workshop Friday Sept 19, 2025 and Saturday Sept 20, 2025 (with Code&Share) at the Royal Danish Library.
https://aulkalender.kb.dk/event/4407115
INTRO:
What is an "object of interest"?

During my eight years of going to the Keskins’ for supper, I was able to squirrel away 4,213 of Füsun’s cigarette butts. Each one of these had touched her rosy lips and entered her mouth, some even touching her tongue and becoming moist, as I would discover when I put my finger on the filter soon after she had stubbed the cigarette out.The stubs, reddened by her lovely lipstick, bore the unique impress of her lips at some moment whose memory was laden with anguish or bliss, making these stubs artifacts of a singular intimacy. Orhan Pamuk, The Museum of Innocence,

Building an imaginary (in a Wiki)
What is 'autonomy'? What does it mean to separate from capital interest?
Not 'one thing' The range of agents, dependencies, flows of capital, and so on, can be difficult to comprehend and is in constant flux.
This, we have tried to capture in our description of the objects, guided by a set of questions that we address directly or indirectly in the different entries to our 'tour guide'
- What is the network that sustains this object?
- How does it evolve through time?
- How does it create value? Or decrease / affect value?
- What is its place/role in techno cultural strategies?
- How does it relate to autonomous infrastructure?
Making maps
"The map is not the territory" (Alfred Korzybski)
Maps are also what 'makes' AI a reality




INSIGHT: AI reconfigures and intersects with many different realities, and exists on different 'planes' (as we will return to in the workshop)
Agenda
Visiting the different 'lands' of AI imaging - looking at the map & practical experimentation (what one can do in this land)
- The Land of Pixels (Pixel Space) // 30 mins, or so - installing software
- The Land of Latents (Latent Space) // 90 mins, or so - making 'LoRAs'
- The Land of GPUs (The Different 'Planes' of AI) // 45 mins, or so - making images using your own computer or Stable Horde (P2P), and spending 'kudos'.
PART ONE: 'The Land of Pixels'
PART TWO: 'The Land of Latents'

Examples of LoRAs (making stories and 'fixing' things)
LoRA "The Incredible Hulk (2008)."

A kitchen in Budapest


The representation of women artists, Louise Bourgeois
-
 An image of Louise Bourgeois with the Real Vision model
An image of Louise Bourgeois with the Real Vision model -
 Louise Bourgeois (Real Vision)
Louise Bourgeois (Real Vision) -
 A screenshot of a search query for Louise Bourgeois
A screenshot of a search query for Louise Bourgeois -
 Selected images from the search results
Selected images from the search results -
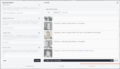 Annotations for the dataset in the Draw Thing interface
Annotations for the dataset in the Draw Thing interface -
 An image generated by Real Vision with LoRA
An image generated by Real Vision with LoRA -
 An image generated by Real Vision with LoRA
An image generated by Real Vision with LoRA







Men washing the dishes




Women fixing airplanes




Men fixing airplanes (by comparison)




Fixing a street in Aarhus?
What are we going to fix? What stories are we going to tell?
Practical example: make a LoRA with Draw Things
- Open Draw Things -> Go to 'PEFT'
- Select a "Base Model" (to fine-tune) // maybe install a 'light' one first to speed up things
- Name your LoRA & Select a 'trigger word'
- Define 'Training Steps' (scroll down to find), set til e.g., 1,000 // the more, the longer the wait
- Add images to train on. 12 images will work. We have prepared a folder as an option.
- Annotate the images // what to think about - when annotating?
- Start training ..... WAIT and WAIT and WAIT (for more than an hour)
Discussion while 'baking' the LoRA
For example:
- How to think of images?
- How to work conceptually?
- How to annotate and what to think of?
- The relation between prompts and models?
- How to make pipelines of models/dataset?
- ?
PART THREE: 'The Land of GPUs (Materials/Organisations) ' ... on the different 'planes' of AI


