LoRA: Difference between revisions
No edit summary |
|||
| (108 intermediate revisions by 2 users not shown) | |||
| Line 1: | Line 1: | ||
== | == LoRA == | ||
[[File:Hulk-lora.png|none|LoRA "The Incredible Hulk (2008)."[1]|thumb|600x600px]] | |||
To | On his personal page on the CivitAI website, the user BigHeadTF promotes his recent creation, a small model called "The Incredible Hulk (2008)." Compared to earlier movies of the Hulk, the 2008 version shows a tormented Bruce Banner who transforms into a green creature with "detailed musculature, dark green skin, and an almost tragic sense of isolation".[2] The model helps generate characters resembling this iconic version of Hulk in new images. | ||
To demonstrate the capabilities of his model, BigHeadTF has selected a few pictures he created with the LoRA. Hulk is in turn depicted as cajoling a teddy bear or crossdressing as Shrek's Princess Fiona. The images play with the contrast between Hulk's overblown virility and childlike or female connotations. The images demonstrate the model's ability to expand the hero's universe into other registers or fictional worlds. "The Incredible Hulk (2008)" doesn't just reproduce faithfully existing images of Hulk, it also opens new avenues for creation and combinations for the green hero. | |||
This blend of pop and remix culture that strives on the blurring of boundaries between genres infuses a large number of creations made with generative AI. However BigHeadTF shares more than images, he also offers the software component that makes his images distinctive. The model he distributes on his page is called a LoRA. The most famous models such as Stable Diffusion or Flux are rather general-purpose. These 'base' or 'foundation' models can be used to generate images in many styles and can handle a huge variety of prompts. But they may show limitations when a user wants a specific output such as a particular genre of manga, a style that emulates black and white film noir or when an improvement is needed for some details (specific hands positions, etc) or to produce legible text. This is where LoRAs come in. A LoRA is a smaller model created with a technique that makes it possible to improve the performance of a base model on a given task. | |||
=== A technical primer === | |||
Initially developed for LLMs, the Low-Rank Adaptation (LoRA) technique is a fine-tuning method that freezes an existing model and inserts a smaller number of weights to adjust the model's behaviour to a particular need. Instead of a full retraining of the model, LoRAs only require the training of the weights that have been inserted in the model's attention layers.[3] Therefore LoRAs are quite lightweight and able to leverage the capabilities of larger models. Users equipped with a consumer-grade [[GPU]] can train their own LoRAs reasonably fast (on a mac M3, a LoRA can be produced in 30 minutes). LoRAs are quite popular within communities of amateurs and developers alike. At the time of writing, the AI platform Hugging Face lists 71,312 LoRAs. | |||
=== What is the network that sustains this object? === | |||
[[File:Image-baking.png|none|thumb|600x600px|Making a Lora is like baking a cake, a post by knxo on CivitAI.[4]]] | |||
The process of LoRA training is very similar to training a model, but at a different scale. Even if it requires dramatically less compute, it still involves the same kind of highly complex technical decisions. In fact, training a LoRA mobilizes the whole network of operation of decentralized image generation and offers a privileged view on its mode of production. | |||
==== Software dependencies ==== | |||
Various layers of software libraries tame this complexity. A highly skilled user can train a LoRA locally with a series of scripts like kohya_ss and pore through the vertiginous list of options. Platforms like Hugging Face distribute software libraries (ie. peft) that abstract away the complex integration of the various components such as LoRAs in the AI generation pipeline. And for those who don't want to fiddle with code or lack access to a [[GPU|local GPU]], the option of training LoRA are offered by websites such as Runway ML, Eden AI, [[Hugging Face]] or [[CivitAI]] for different price schemes. | |||
==== LoRA as a contact zone between communities with different expertise ==== | |||
"Making a LoRA is like baking a cake," says a widely read tutorial, ' "a lot of preparation, and then letting it bake. If you didn't properly make the preparations, it will probably be inedible."[5] To guide the wannabe LoRA creator in their journey, a wealth of tutorials and documentation in various forms are available from sources such as subreddits, Discord channels, YouTube videos, forums and the platforms that release the code or offer the training and hosting services. They are diverse in tone and they provide varying forms of expertise. A significant portion of this documentation effort consists in code snippets, detailed explanations of parameters and options, bug reports, detailed instructions for the installation of software, tests of hardware compatibility. They are written by professionals, hackers, amateurs, newbies with access to very different infrastructure. Some take for granted unlimited access to compute whilst others make do with a limited local installation. This diversity reflects the position of LoRAs in the AI ecosystem: between expertise and informed amateurism and between resource hungry and consumer grade technology. Whereas foundational model training still remains in the hands of a (happy?) few, LoRA training opens up a perspective of democratization of the means of production for those who have time, persistence and a small capital to invest. | |||
==== Curation as an operational practice ==== | |||
There is more to LoRA than the technicalities of installing libraries and training. LoRAs are curated objects. Many tutorials begin with a primer on [[dataset]] curation. Fans, artists and amateurs produce an abundant literature on the various questions raised by dataset curation: the identification of sources, the selection of images (criteria of quality, diversity, etc), the annotation (tagging), scale (LoRAs can be trained on datasets containing as little as one image and can include collections of thousands of images). As we said above, typically, a user decides to embark on the adventure of creating a LoRA because available models fail to generate convincing images for a given subject or style. But they don't start from scratch. They identify the model that approximates best their objective and select images to improve the perceived lacks. LoRA curators look for precision and nuances rather than quantity. They go to great length to identify the most representative visuals for the purpose they have in mind, but they don't do that in the abstract. They identify their samples in response to the existing weaknesses of the model's output. | |||
==== Remodelling as rewording ==== | |||
[[File:Screenshot 2025-07-08 at 10.51.10 2.png|alt=Search for the tag dirt_road on the danbooru wiki|none|thumb|600x600px|Search for the tag dirt_road on the danbooru wiki.[6]]] | |||
The objective of LoRA's curation is to form the learning base for remodelling, not modelling. The importance of that distinction is palpable in the various decisions involved in annotating images in the training set. There are different means of annotating images. To select the right one, the annotator must know how the original model has been trained. For photorealistic images, most models have been annotated with a piece of software called BLIP (which stands for Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation).[7]. BLIP produces descriptions in 'natural language' such as "a high resolution photograph of a man sitting on a beach in the moonlight". In the case of LoRAs in anime style, understanding the semantic logic of tagging brings the annotator in the booru universe. Boorus (the word board pronounced in Japanese ) are image boards designed to host collections of animes.[8] Boorus are targets of choice for AI scrapers as they contain huge amounts of images and are frantically annotated by their creators. As Knxo aptly notes: | |||
Danbooru: Danbooru style captioning is based in the Booru tagging system and implemented in all NAI derivatives and mixes which accounts for most SD1.5 non photorealistic models. It commonly appears in the following form "1girl, green_eyes, brown_hair, walking, forest, green_dress, eating, burrito, (sauce)". This tagging style is named after the site, as in <nowiki>https://danbooru.donmai.us/</nowiki>. Whenever you have doubt on the meaning of a tag you can navigate to danbooru, search for the tag and open it's wiki. | |||
Take for example the following, search for the tag "road" when we open it's wiki we will see the exact definition as well as derivative tags like street, sidewalk or alley as well as the amount of times the image has been used(13K). In Practice what this means is that the concept is trained to some degree in NAI based models and mixes. The amount of times the tag appears in danbooru actually correlates to the strength of the training(as NAI was directly trained on Danbooru data). So any concept below 500 coincidences are a bit iffy. Keep that in mind when captioning as sometimes it makes more sense to use a generic tag instead of the proper one, for example "road" appears 13k times while "dirt_road" only does so 395 times. In this particular case using dirt_road shouldn't be problematic as "dirt_road" contains "road" anyway and SD is able to see the association.[9] | |||
The LoRA's creator skills include a knowledge about the cultures from which the underlying model has learned. For the vocabulary and syntax and for the comparative weight given to individual concepts learned by the model. The tagging of the LoRA's dataset mirrors and rewords the tagging of the underlying model. This means that the user gradually develops an acute sense of the model's biases (how it weighs more some terms than others, and exclude/ignore terms). In that context, tagging is an intricate dance with the bias in order to reverse the problem or work with it. Even if the object of the annotator's effort might seem superficial (adding yet another LoRA for a character that is already featured in hundreds of others), it represents a form of specialized conceptual labour. This testifies to the level of competence in visual culture that is expected from fans and advanced users and their ability to think about image beyond immediate representation but more structurally and abstractly, as well as programmatically. | |||
==== Negotiating the boundaries of property and identity ==== | |||
Curation involve ethical decisions that are often mentioned in tutorials and posts. Is it OK to scrape from any source? When is appropriation legitimate? The implications of these questions become apparent when users have to take position for or against making style LoRAs. A style LoRA is a small adapter that can be included in a generative pipeline in order to make images in the style of a given artist. Fans are caught between their desire to engage more deeply with the universe of their favourite authors, but they are also aware that they might infringe on their right. In fan communities, to reproduce a character is a well-accepted practice. The site DevianArt features endless crowds of unicorns made by anime lovers. To enable style mimicry is perceived as going a step further. This time is to substitute oneself to the author. A dilemma of the same kind occurs when users produce LoRAs that either make it easier to generate realistic images or that make it possible to generate a convincing representation of an existing person. The production of deepfake is often prohibited in the notice that accompanies models. Nevertheless, a quick search on CivitAI reveals an impressive number of LoRAs impersonating actors, politicians and porn stars. Which brings the platform to the limit of legality. | |||
==== Another distribution of labour ==== | |||
The curatorial practice of LoRA creators is very different than the one used to assemble large-scale datasets for foundational models. The curators of huge datasets such as [[LAION]] privilege broad scraping and an automatic process. In the case of LoRAs, the creators are manually picking, and, even when they resort to scraping, they visually monitor the results. Each individual image is validated by the curator. Further, this curatorial practice forms part of an integrated whole. The same person selects the images, writes the captions and trains the LoRA. This again sets the mode of production of LoRAs apart from big models' where separate entities deal with the dataset's curation and the training of the model. But we should not simply oppose the craft of LoRA curators to the industrial approach of large dataset creators as they depend on each other. Either for their mere existence, - no LoRA without underlying model - , or to gain value, - a large model becomes more popular if a LoRA extends its capabilities. | |||
==== Baking the cake ==== | |||
When the dataset is ready, the training phase begins. Training solicits a different set of skills and knowledge. If some users quickly put together a collection of images and train the LoRA with default parameters while hoping for the best, experienced users delve into a vertiginous list of parameters to 'bake the perfect cake'. To achieve this goal, they must strike a balance between the ideal amount of training and the available material infrastructure, as well as the time during which the machine can be 'monopolized' by the training process. On a personal laptop, better results can be obtained with 24 hours of training. But this means that the machine won't be available for that time. And 24 hours might be long to check the results. Training is time management combined with an evaluation of resource availability that the user must learn to translate into a selection of arcane parameters such as epochs, batch size and steps. The user faces another challenge: the problem of 'overcooking'. A LoRA is 'overcooked' when it reproduces too literally its training content. In the computer science jargon, this effect called ''overfitting'' is correlated to a selection of parameters that make the model memorize the noise and other irrelevant information from the dataset.[10] When making a LoRA for adding the representation of a particular object in the model, an example of overfitting would be that the model would not only generate images with this object, but also include elements of the background of the training images disrupting the visual consistency of the newly created picture. For many, baking a LoRA is an art more than a science and the choice of parameters is influenced by reports circulating on an extensive network of platforms that range from Reddit and [[CivitAI]] to GitHub and [[Hugging Face]] to Arxiv. At the training stage, the network extends from the sites that provide images and curatorial resources to a mix of highly technical pages and sites where informal conversation can be had. | |||
The length of the process combined with its opaque nature imposes many cycles of iteration. The training can be stalled after a number of steps. It can abruptly end with a sibylline error message. The computer may freeze. The user may run out of credits. Or, the results may be sorely disappointing. All these problems trigger search queries, intense readings of manuals, discussions on chats and forums, the writing of desperate X posts and soul searching blog entries. The user navigates these sites piecing out the information, seeking answers and emotional support. Finding reliable sources of information, they weave a dense network without which they wouldn't manage to make sense of the enigmatic behaviour of their 'oven'. They have to learn to balance the authoritative voices of the authors of the software documentation and the rawer commentaries of those who, like themselves, struggle to make it work. It is not rare to find the users who share tips and tutorials express different grades of confidence regarding their choices about loss functions or schedulers. With sometimes a clear admission of powerlessness: "no idea just leave it at 1". | |||
=== How does it create value? Or decrease / affect value? === | |||
LoRAs are definitely objects of interest in the communities of genAI creators. Publishing a good LoRA raises the a user's status. It sets them apart in the extent to which the small model provides capabilities desired by other fans and creators. It helps to bypass limitations and expand the range of potential representations. Technically, the LoRA creator gains a knowledge and the writing of tutorials serve to share one's experience but also to attract visibility and legitimate one's status. For a platform such as CivitAI, the creation of LoRAs is encouraged. A dedicated page of the site's education section offers several resources and a glossary.[11] Hosting LoRAs has a clear advantage. It adds value to the base models. Combined with LoRAs, their capabilities are expanded. Essentially the ever growing offer allows them to reach to the specific tastes and interests of variegated groups of users, therefore extending the platform's audience. | |||
[[File:Image-bounty-lora-rules.png|none|thumb|640x640px|Rewards for the best creative use of a LoRA.[12]]] | |||
==== Market for LoRAs, the power of demand ==== | |||
The popularity of LoRA in terms of offer and demand gives a peek into the economy of visibility on the CivitAI platform. Users produce and consume these small models abundantly. To the degree that some of them decry a "mass production".[13] Many transactions on the platform concern LoRAs. Using the platform currency, buzz, many users posts '''[https://civitai.com/articles/17883/multiple-characters-bounty-results bounties]''' [14] where they describe the desired characteristics of a needed LoRA. And LoRA creators '''[https://civitai.com/articles/2684/how-i-made-over-dollar1000-in-3-months-selling-loras offer their services]''' [15] against remuneration or for free. LoRA's expertise is sought after. Yet, this expertise is not necessarily monetised. Many users ask others ideas for LoRAs that they subsequently generate for free and share with the whole community. Even if there is no financial return, the user gains visibility and is granted status among their peers. This motivates some users to offer buzz rewards to those who are using their LoRA creatively and thereby demonstrate their small model's brilliance and relevance. This testifies to the logic of an economy of visibility where what is sought after is a missing link between large models and user practice. In this gap, the skills of the LoRA creator is worth its salt. But through LoRA, what the platform and the LoRA makers are trying to reach is the elusive demand. And the more abundant the offer becomes, the most scarce and therefore valuable demand becomes. In the context of over production and sharing, of saturation of the imaginary, the LoRA is a device to fill the last remaining gaps. It is also a device to find the last subjects for whom something remains to be desired. | |||
=== What is its place/role in techno cultural strategies? === | |||
[[File:Civitai-loras-q9.png|none|alt=Screengrab of the LoRA page on the civit.ai platform|Screengrab of the LoRA page on the civit.ai platform|thumb|400x400px]]A quick look at the LoRA page on CivitAI gives an idea of the forms of gender representation that dominates the platform. When discussing the site's visuals, a participant to a workshop we gave in the context of Xeno Visual Studies in Madrid eructed "this is incel culture". And indeed a large portion of the LoRAs feature female characters with large breasts and bodybuilded male heroes. If parodies and critiques of these stereotypes also circulate on the platform as the opening vignette of this entry demonstrates, they remain limited in numbers. | |||
While we experimented ourselves with the creation of LoRAs, we wondered how we could begin responding to the lack of diversity in the representations of women in both LoRAs and models. Our small experiment took the form of a LoRA to represent the artist Louise Bourgeois. Indeed prompting a model such as Real Vision with a query such as "The artist Louise Bourgeois working in her studio" resulted in an image of an older woman dressed in a contemporary attire with a vague physical likeness to the artist. Assembling a dataset from online and offline images, we ended up with a dozen candidates which we annotated in the Draw Thing software locally. Subsequently we used Draw Things to train a LoRA with RealVision as our base model and explored the results. | |||
<gallery> | |||
File:Image-Bourgeopis-2.png|An image of Louise Bourgeois with the Real Vision model | |||
File:Image-LBourgeois-realVision.png|Louise Bourgeois (Real Vision) | |||
File:Image-search query louise bourgeois.png|A screenshot of a search query for Louise Bourgeois | |||
File:Image-selected images.png|Selected images from the search results | |||
File:Image-annotating the dataset.png|Annotations for the dataset in the Draw Thing interface | |||
File:Image-generated image with LoRA.png|An image generated by Real Vision with LoRA | |||
File:Image-lora-bourgeois.png|An image generated by Real Vision with LoRA | |||
</gallery> | |||
Interestingly, with the LoRA, the same model managed to produce a more resembling character. The facial expression with the ironic smile characterizing Bourgeois was present. The general texture of the artworks surrounding Bourgeois were also closer to her work although they remained more academic in style. Instead of showing her drawing at the studio's table, the model was now showing her in contact with the sculptures. Whilst this experiment remained limited and the portraits of Bourgeois were still rather crude, the potential for an engagement with the artist's representation clearly appeared to us. However, this left us with a difficult question. If there is an undeniable production of technical knowledge and skill and (as we develop below) a gain in autonomy from the practice of LoRA creation, how could this potential of technical emancipation be aligned with a different aesthetics and politics of representation? | |||
=== How does it relate to autonomous infrastructure? === | |||
The precondition for the existence of LoRA is the realisation that base models cannot generate everything, that they are partial and biased. This technique allows to regain partial control over the training, a part of the technical process that is usually reserved to a handful of companies. In that perspective, the existence of LoRAs evokes the possibility of a re-appropriation of the model via fine-tuning. Even if not complete, this helps users regain some form of autonomy from large models providers. In particular because their needs are defined bottom-up. | |||
As written above, the interest for LoRAs corresponds for many users to the realisation that the interaction with AI generators is showing some limits. If these limits are first felt at the level of content, the journey of LoRA creation confronts the users to another important limitation: the availability of hardware. LoRA training provokes an engagement with the material plane of genAI ecosystem and its logistics. The materiality of the system becomes palpable either through its costs, or through alternative means of accessing a highly coveted GPU. LoRA creation makes the user aware of the genAI ecosystem economy as access to compute is 'linked' to different forms of [[currencies]]. Be it in platforms such as CivitAI, the buzz, or in networks such as Stable Horde, kudos. This being said, fine-tuning techniques benefit from the evolution of the material conditions. As the technical requirements become lighter, LoRA production can happen in different environments. In privileged countries, advanced users can train locally on their own machine with consumer-grade GPUs. With a small budget, LoRAs can be trained online. Infrastructurally speaking, edge AI and 'community' platforms are in a position to meet the needs for LoRA training and therefore decentralize a step further the training process. But to date, peer to peer networks such as Stable Horde are still limited to inference. | |||
The largest gain is in term of literacy and understanding of the training process more generally. Indeed as LoRAs are miniature models, the skills and expertise related to curation, sourcing, annotation, and model semantics are being developed through a peer to peer effort in communities of amateurs and image makers. This knowledge that initially pertained to niches of specialists is being popularized, shared and translated to numerous cultural contexts. If there are still many obstacles to a radical delinking from platforms, there are many encouraging signs that point to a potential convergence between communities and a less centrally controlled infrastructure. LoRA creation might not be the undoing of the centralizing power of hegemonic platforms, far from there. But it can be a step in that direction. | |||
[1] BigHeadTF, ''The Incredible Hulk (2008) – V1'', Civitai, published February 18, 2025, accessed August 18, 2025, https://civitai.com/models/1266100/the-incredible-hulk-2008. | |||
[2] BigHeadTF, ''The Incredible Hulk (2008) – V1''. | |||
[3] Efrat, “LoRA Under the Hood: How It Really Works in Visual Generative AI,” ''Medium'', accessed August 18, 2025, https://medium.com/@efrat_37973/lora-under-the-hood-how-it-really-works-in-visual-generative-ai-e6c10611b461. | |||
[4] knxo, “Making a LoRA Is Like Baking a Cake,” ''Civitai'', published July 10, 2024, accessed August 18, 2025, https://civitai.com/articles/138/making-a-lora-is-like-baking-a-cake. | |||
[5] knxo, “Making a LoRA Is Like Baking a Cake.” | |||
[6] Danbooru, "Dirt Road", ''Danbooru'', accessed August 18, 2025, https://danbooru.donmai.us/posts?tags=dirt_road | |||
[7] Junnan Li, Khaliq Ahsen'', BLIP: Bootstrapping Language-Image Pre-training'', GitHub repository, Salesforce, 2022, https://github.com/salesforce/BLIP. | |||
[8] Wikipedia, “Imageboard,” last modified August 2025, accessed August 18, 2025, https://en.wikipedia.org/wiki/Imageboard#Booru. | |||
[9] knxo, “Making a LoRA Is Like Baking a Cake.” | |||
[10] IBM, “What Is Overfitting?” ''IBM Think'', last modified October 15, 2021, accessed August 18, 2025, https://www.ibm.com/think/topics/overfitting. | |||
[11] Civitai, “LoRA Training Glossary,” ''Civitai Education'', accessed August 18, 2025, https://education.civitai.com/lora-training-glossary/. | |||
[12] tehalex86, ''5K CrazyWhatever'', Civitai, accessed August 18, 2025, https://civitai.com/bounties/8690/5k-crazywhatever. | |||
[13] Stagnation, “The Most Prolific Character LoRAs in Existence by FAR,” ''Civitai'', published February 2, 2024, accessed August 18, 2025, https://civitai.com/articles/3940/the-most-prolific-character-loras-in-existence-by-far. | |||
[14] ColonelJay, "Multiple characters Bounty Results!", ''Civitai'', published August 16, 2025, accessed August 21, 2025, https://civitai.com/articles/17883/multiple-characters-bounty-results | |||
[15] extrafuzzy, "How I made over $1000 in 3 months selling LoRAs", ''Civitai'', published October 22, 2023, accessed August 21, 2025, https://civitai.com/articles/2684/how-i-made-over-dollar1000-in-3-months-selling-loras. | |||
[[Category:Objects of Interest and Necessity]] | |||
Latest revision as of 16:40, 21 August 2025
LoRA

On his personal page on the CivitAI website, the user BigHeadTF promotes his recent creation, a small model called "The Incredible Hulk (2008)." Compared to earlier movies of the Hulk, the 2008 version shows a tormented Bruce Banner who transforms into a green creature with "detailed musculature, dark green skin, and an almost tragic sense of isolation".[2] The model helps generate characters resembling this iconic version of Hulk in new images.
To demonstrate the capabilities of his model, BigHeadTF has selected a few pictures he created with the LoRA. Hulk is in turn depicted as cajoling a teddy bear or crossdressing as Shrek's Princess Fiona. The images play with the contrast between Hulk's overblown virility and childlike or female connotations. The images demonstrate the model's ability to expand the hero's universe into other registers or fictional worlds. "The Incredible Hulk (2008)" doesn't just reproduce faithfully existing images of Hulk, it also opens new avenues for creation and combinations for the green hero.
This blend of pop and remix culture that strives on the blurring of boundaries between genres infuses a large number of creations made with generative AI. However BigHeadTF shares more than images, he also offers the software component that makes his images distinctive. The model he distributes on his page is called a LoRA. The most famous models such as Stable Diffusion or Flux are rather general-purpose. These 'base' or 'foundation' models can be used to generate images in many styles and can handle a huge variety of prompts. But they may show limitations when a user wants a specific output such as a particular genre of manga, a style that emulates black and white film noir or when an improvement is needed for some details (specific hands positions, etc) or to produce legible text. This is where LoRAs come in. A LoRA is a smaller model created with a technique that makes it possible to improve the performance of a base model on a given task.
A technical primer
Initially developed for LLMs, the Low-Rank Adaptation (LoRA) technique is a fine-tuning method that freezes an existing model and inserts a smaller number of weights to adjust the model's behaviour to a particular need. Instead of a full retraining of the model, LoRAs only require the training of the weights that have been inserted in the model's attention layers.[3] Therefore LoRAs are quite lightweight and able to leverage the capabilities of larger models. Users equipped with a consumer-grade GPU can train their own LoRAs reasonably fast (on a mac M3, a LoRA can be produced in 30 minutes). LoRAs are quite popular within communities of amateurs and developers alike. At the time of writing, the AI platform Hugging Face lists 71,312 LoRAs.
What is the network that sustains this object?

The process of LoRA training is very similar to training a model, but at a different scale. Even if it requires dramatically less compute, it still involves the same kind of highly complex technical decisions. In fact, training a LoRA mobilizes the whole network of operation of decentralized image generation and offers a privileged view on its mode of production.
Software dependencies
Various layers of software libraries tame this complexity. A highly skilled user can train a LoRA locally with a series of scripts like kohya_ss and pore through the vertiginous list of options. Platforms like Hugging Face distribute software libraries (ie. peft) that abstract away the complex integration of the various components such as LoRAs in the AI generation pipeline. And for those who don't want to fiddle with code or lack access to a local GPU, the option of training LoRA are offered by websites such as Runway ML, Eden AI, Hugging Face or CivitAI for different price schemes.
LoRA as a contact zone between communities with different expertise
"Making a LoRA is like baking a cake," says a widely read tutorial, ' "a lot of preparation, and then letting it bake. If you didn't properly make the preparations, it will probably be inedible."[5] To guide the wannabe LoRA creator in their journey, a wealth of tutorials and documentation in various forms are available from sources such as subreddits, Discord channels, YouTube videos, forums and the platforms that release the code or offer the training and hosting services. They are diverse in tone and they provide varying forms of expertise. A significant portion of this documentation effort consists in code snippets, detailed explanations of parameters and options, bug reports, detailed instructions for the installation of software, tests of hardware compatibility. They are written by professionals, hackers, amateurs, newbies with access to very different infrastructure. Some take for granted unlimited access to compute whilst others make do with a limited local installation. This diversity reflects the position of LoRAs in the AI ecosystem: between expertise and informed amateurism and between resource hungry and consumer grade technology. Whereas foundational model training still remains in the hands of a (happy?) few, LoRA training opens up a perspective of democratization of the means of production for those who have time, persistence and a small capital to invest.
Curation as an operational practice
There is more to LoRA than the technicalities of installing libraries and training. LoRAs are curated objects. Many tutorials begin with a primer on dataset curation. Fans, artists and amateurs produce an abundant literature on the various questions raised by dataset curation: the identification of sources, the selection of images (criteria of quality, diversity, etc), the annotation (tagging), scale (LoRAs can be trained on datasets containing as little as one image and can include collections of thousands of images). As we said above, typically, a user decides to embark on the adventure of creating a LoRA because available models fail to generate convincing images for a given subject or style. But they don't start from scratch. They identify the model that approximates best their objective and select images to improve the perceived lacks. LoRA curators look for precision and nuances rather than quantity. They go to great length to identify the most representative visuals for the purpose they have in mind, but they don't do that in the abstract. They identify their samples in response to the existing weaknesses of the model's output.
Remodelling as rewording

The objective of LoRA's curation is to form the learning base for remodelling, not modelling. The importance of that distinction is palpable in the various decisions involved in annotating images in the training set. There are different means of annotating images. To select the right one, the annotator must know how the original model has been trained. For photorealistic images, most models have been annotated with a piece of software called BLIP (which stands for Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation).[7]. BLIP produces descriptions in 'natural language' such as "a high resolution photograph of a man sitting on a beach in the moonlight". In the case of LoRAs in anime style, understanding the semantic logic of tagging brings the annotator in the booru universe. Boorus (the word board pronounced in Japanese ) are image boards designed to host collections of animes.[8] Boorus are targets of choice for AI scrapers as they contain huge amounts of images and are frantically annotated by their creators. As Knxo aptly notes:
Danbooru: Danbooru style captioning is based in the Booru tagging system and implemented in all NAI derivatives and mixes which accounts for most SD1.5 non photorealistic models. It commonly appears in the following form "1girl, green_eyes, brown_hair, walking, forest, green_dress, eating, burrito, (sauce)". This tagging style is named after the site, as in https://danbooru.donmai.us/. Whenever you have doubt on the meaning of a tag you can navigate to danbooru, search for the tag and open it's wiki.
Take for example the following, search for the tag "road" when we open it's wiki we will see the exact definition as well as derivative tags like street, sidewalk or alley as well as the amount of times the image has been used(13K). In Practice what this means is that the concept is trained to some degree in NAI based models and mixes. The amount of times the tag appears in danbooru actually correlates to the strength of the training(as NAI was directly trained on Danbooru data). So any concept below 500 coincidences are a bit iffy. Keep that in mind when captioning as sometimes it makes more sense to use a generic tag instead of the proper one, for example "road" appears 13k times while "dirt_road" only does so 395 times. In this particular case using dirt_road shouldn't be problematic as "dirt_road" contains "road" anyway and SD is able to see the association.[9]
The LoRA's creator skills include a knowledge about the cultures from which the underlying model has learned. For the vocabulary and syntax and for the comparative weight given to individual concepts learned by the model. The tagging of the LoRA's dataset mirrors and rewords the tagging of the underlying model. This means that the user gradually develops an acute sense of the model's biases (how it weighs more some terms than others, and exclude/ignore terms). In that context, tagging is an intricate dance with the bias in order to reverse the problem or work with it. Even if the object of the annotator's effort might seem superficial (adding yet another LoRA for a character that is already featured in hundreds of others), it represents a form of specialized conceptual labour. This testifies to the level of competence in visual culture that is expected from fans and advanced users and their ability to think about image beyond immediate representation but more structurally and abstractly, as well as programmatically.
Negotiating the boundaries of property and identity
Curation involve ethical decisions that are often mentioned in tutorials and posts. Is it OK to scrape from any source? When is appropriation legitimate? The implications of these questions become apparent when users have to take position for or against making style LoRAs. A style LoRA is a small adapter that can be included in a generative pipeline in order to make images in the style of a given artist. Fans are caught between their desire to engage more deeply with the universe of their favourite authors, but they are also aware that they might infringe on their right. In fan communities, to reproduce a character is a well-accepted practice. The site DevianArt features endless crowds of unicorns made by anime lovers. To enable style mimicry is perceived as going a step further. This time is to substitute oneself to the author. A dilemma of the same kind occurs when users produce LoRAs that either make it easier to generate realistic images or that make it possible to generate a convincing representation of an existing person. The production of deepfake is often prohibited in the notice that accompanies models. Nevertheless, a quick search on CivitAI reveals an impressive number of LoRAs impersonating actors, politicians and porn stars. Which brings the platform to the limit of legality.
Another distribution of labour
The curatorial practice of LoRA creators is very different than the one used to assemble large-scale datasets for foundational models. The curators of huge datasets such as LAION privilege broad scraping and an automatic process. In the case of LoRAs, the creators are manually picking, and, even when they resort to scraping, they visually monitor the results. Each individual image is validated by the curator. Further, this curatorial practice forms part of an integrated whole. The same person selects the images, writes the captions and trains the LoRA. This again sets the mode of production of LoRAs apart from big models' where separate entities deal with the dataset's curation and the training of the model. But we should not simply oppose the craft of LoRA curators to the industrial approach of large dataset creators as they depend on each other. Either for their mere existence, - no LoRA without underlying model - , or to gain value, - a large model becomes more popular if a LoRA extends its capabilities.
Baking the cake
When the dataset is ready, the training phase begins. Training solicits a different set of skills and knowledge. If some users quickly put together a collection of images and train the LoRA with default parameters while hoping for the best, experienced users delve into a vertiginous list of parameters to 'bake the perfect cake'. To achieve this goal, they must strike a balance between the ideal amount of training and the available material infrastructure, as well as the time during which the machine can be 'monopolized' by the training process. On a personal laptop, better results can be obtained with 24 hours of training. But this means that the machine won't be available for that time. And 24 hours might be long to check the results. Training is time management combined with an evaluation of resource availability that the user must learn to translate into a selection of arcane parameters such as epochs, batch size and steps. The user faces another challenge: the problem of 'overcooking'. A LoRA is 'overcooked' when it reproduces too literally its training content. In the computer science jargon, this effect called overfitting is correlated to a selection of parameters that make the model memorize the noise and other irrelevant information from the dataset.[10] When making a LoRA for adding the representation of a particular object in the model, an example of overfitting would be that the model would not only generate images with this object, but also include elements of the background of the training images disrupting the visual consistency of the newly created picture. For many, baking a LoRA is an art more than a science and the choice of parameters is influenced by reports circulating on an extensive network of platforms that range from Reddit and CivitAI to GitHub and Hugging Face to Arxiv. At the training stage, the network extends from the sites that provide images and curatorial resources to a mix of highly technical pages and sites where informal conversation can be had.
The length of the process combined with its opaque nature imposes many cycles of iteration. The training can be stalled after a number of steps. It can abruptly end with a sibylline error message. The computer may freeze. The user may run out of credits. Or, the results may be sorely disappointing. All these problems trigger search queries, intense readings of manuals, discussions on chats and forums, the writing of desperate X posts and soul searching blog entries. The user navigates these sites piecing out the information, seeking answers and emotional support. Finding reliable sources of information, they weave a dense network without which they wouldn't manage to make sense of the enigmatic behaviour of their 'oven'. They have to learn to balance the authoritative voices of the authors of the software documentation and the rawer commentaries of those who, like themselves, struggle to make it work. It is not rare to find the users who share tips and tutorials express different grades of confidence regarding their choices about loss functions or schedulers. With sometimes a clear admission of powerlessness: "no idea just leave it at 1".
How does it create value? Or decrease / affect value?
LoRAs are definitely objects of interest in the communities of genAI creators. Publishing a good LoRA raises the a user's status. It sets them apart in the extent to which the small model provides capabilities desired by other fans and creators. It helps to bypass limitations and expand the range of potential representations. Technically, the LoRA creator gains a knowledge and the writing of tutorials serve to share one's experience but also to attract visibility and legitimate one's status. For a platform such as CivitAI, the creation of LoRAs is encouraged. A dedicated page of the site's education section offers several resources and a glossary.[11] Hosting LoRAs has a clear advantage. It adds value to the base models. Combined with LoRAs, their capabilities are expanded. Essentially the ever growing offer allows them to reach to the specific tastes and interests of variegated groups of users, therefore extending the platform's audience.

Market for LoRAs, the power of demand
The popularity of LoRA in terms of offer and demand gives a peek into the economy of visibility on the CivitAI platform. Users produce and consume these small models abundantly. To the degree that some of them decry a "mass production".[13] Many transactions on the platform concern LoRAs. Using the platform currency, buzz, many users posts bounties [14] where they describe the desired characteristics of a needed LoRA. And LoRA creators offer their services [15] against remuneration or for free. LoRA's expertise is sought after. Yet, this expertise is not necessarily monetised. Many users ask others ideas for LoRAs that they subsequently generate for free and share with the whole community. Even if there is no financial return, the user gains visibility and is granted status among their peers. This motivates some users to offer buzz rewards to those who are using their LoRA creatively and thereby demonstrate their small model's brilliance and relevance. This testifies to the logic of an economy of visibility where what is sought after is a missing link between large models and user practice. In this gap, the skills of the LoRA creator is worth its salt. But through LoRA, what the platform and the LoRA makers are trying to reach is the elusive demand. And the more abundant the offer becomes, the most scarce and therefore valuable demand becomes. In the context of over production and sharing, of saturation of the imaginary, the LoRA is a device to fill the last remaining gaps. It is also a device to find the last subjects for whom something remains to be desired.
What is its place/role in techno cultural strategies?

A quick look at the LoRA page on CivitAI gives an idea of the forms of gender representation that dominates the platform. When discussing the site's visuals, a participant to a workshop we gave in the context of Xeno Visual Studies in Madrid eructed "this is incel culture". And indeed a large portion of the LoRAs feature female characters with large breasts and bodybuilded male heroes. If parodies and critiques of these stereotypes also circulate on the platform as the opening vignette of this entry demonstrates, they remain limited in numbers.
While we experimented ourselves with the creation of LoRAs, we wondered how we could begin responding to the lack of diversity in the representations of women in both LoRAs and models. Our small experiment took the form of a LoRA to represent the artist Louise Bourgeois. Indeed prompting a model such as Real Vision with a query such as "The artist Louise Bourgeois working in her studio" resulted in an image of an older woman dressed in a contemporary attire with a vague physical likeness to the artist. Assembling a dataset from online and offline images, we ended up with a dozen candidates which we annotated in the Draw Thing software locally. Subsequently we used Draw Things to train a LoRA with RealVision as our base model and explored the results.
-
 An image of Louise Bourgeois with the Real Vision model
An image of Louise Bourgeois with the Real Vision model -
 Louise Bourgeois (Real Vision)
Louise Bourgeois (Real Vision) -
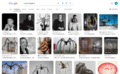 A screenshot of a search query for Louise Bourgeois
A screenshot of a search query for Louise Bourgeois -
 Selected images from the search results
Selected images from the search results -
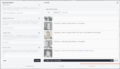 Annotations for the dataset in the Draw Thing interface
Annotations for the dataset in the Draw Thing interface -
 An image generated by Real Vision with LoRA
An image generated by Real Vision with LoRA -
 An image generated by Real Vision with LoRA
An image generated by Real Vision with LoRA







Interestingly, with the LoRA, the same model managed to produce a more resembling character. The facial expression with the ironic smile characterizing Bourgeois was present. The general texture of the artworks surrounding Bourgeois were also closer to her work although they remained more academic in style. Instead of showing her drawing at the studio's table, the model was now showing her in contact with the sculptures. Whilst this experiment remained limited and the portraits of Bourgeois were still rather crude, the potential for an engagement with the artist's representation clearly appeared to us. However, this left us with a difficult question. If there is an undeniable production of technical knowledge and skill and (as we develop below) a gain in autonomy from the practice of LoRA creation, how could this potential of technical emancipation be aligned with a different aesthetics and politics of representation?
How does it relate to autonomous infrastructure?
The precondition for the existence of LoRA is the realisation that base models cannot generate everything, that they are partial and biased. This technique allows to regain partial control over the training, a part of the technical process that is usually reserved to a handful of companies. In that perspective, the existence of LoRAs evokes the possibility of a re-appropriation of the model via fine-tuning. Even if not complete, this helps users regain some form of autonomy from large models providers. In particular because their needs are defined bottom-up.
As written above, the interest for LoRAs corresponds for many users to the realisation that the interaction with AI generators is showing some limits. If these limits are first felt at the level of content, the journey of LoRA creation confronts the users to another important limitation: the availability of hardware. LoRA training provokes an engagement with the material plane of genAI ecosystem and its logistics. The materiality of the system becomes palpable either through its costs, or through alternative means of accessing a highly coveted GPU. LoRA creation makes the user aware of the genAI ecosystem economy as access to compute is 'linked' to different forms of currencies. Be it in platforms such as CivitAI, the buzz, or in networks such as Stable Horde, kudos. This being said, fine-tuning techniques benefit from the evolution of the material conditions. As the technical requirements become lighter, LoRA production can happen in different environments. In privileged countries, advanced users can train locally on their own machine with consumer-grade GPUs. With a small budget, LoRAs can be trained online. Infrastructurally speaking, edge AI and 'community' platforms are in a position to meet the needs for LoRA training and therefore decentralize a step further the training process. But to date, peer to peer networks such as Stable Horde are still limited to inference.
The largest gain is in term of literacy and understanding of the training process more generally. Indeed as LoRAs are miniature models, the skills and expertise related to curation, sourcing, annotation, and model semantics are being developed through a peer to peer effort in communities of amateurs and image makers. This knowledge that initially pertained to niches of specialists is being popularized, shared and translated to numerous cultural contexts. If there are still many obstacles to a radical delinking from platforms, there are many encouraging signs that point to a potential convergence between communities and a less centrally controlled infrastructure. LoRA creation might not be the undoing of the centralizing power of hegemonic platforms, far from there. But it can be a step in that direction.
[1] BigHeadTF, The Incredible Hulk (2008) – V1, Civitai, published February 18, 2025, accessed August 18, 2025, https://civitai.com/models/1266100/the-incredible-hulk-2008.
[2] BigHeadTF, The Incredible Hulk (2008) – V1.
[3] Efrat, “LoRA Under the Hood: How It Really Works in Visual Generative AI,” Medium, accessed August 18, 2025, https://medium.com/@efrat_37973/lora-under-the-hood-how-it-really-works-in-visual-generative-ai-e6c10611b461.
[4] knxo, “Making a LoRA Is Like Baking a Cake,” Civitai, published July 10, 2024, accessed August 18, 2025, https://civitai.com/articles/138/making-a-lora-is-like-baking-a-cake.
[5] knxo, “Making a LoRA Is Like Baking a Cake.”
[6] Danbooru, "Dirt Road", Danbooru, accessed August 18, 2025, https://danbooru.donmai.us/posts?tags=dirt_road
[7] Junnan Li, Khaliq Ahsen, BLIP: Bootstrapping Language-Image Pre-training, GitHub repository, Salesforce, 2022, https://github.com/salesforce/BLIP.
[8] Wikipedia, “Imageboard,” last modified August 2025, accessed August 18, 2025, https://en.wikipedia.org/wiki/Imageboard#Booru.
[9] knxo, “Making a LoRA Is Like Baking a Cake.”
[10] IBM, “What Is Overfitting?” IBM Think, last modified October 15, 2021, accessed August 18, 2025, https://www.ibm.com/think/topics/overfitting.
[11] Civitai, “LoRA Training Glossary,” Civitai Education, accessed August 18, 2025, https://education.civitai.com/lora-training-glossary/.
[12] tehalex86, 5K CrazyWhatever, Civitai, accessed August 18, 2025, https://civitai.com/bounties/8690/5k-crazywhatever.
[13] Stagnation, “The Most Prolific Character LoRAs in Existence by FAR,” Civitai, published February 2, 2024, accessed August 18, 2025, https://civitai.com/articles/3940/the-most-prolific-character-loras-in-existence-by-far.
[14] ColonelJay, "Multiple characters Bounty Results!", Civitai, published August 16, 2025, accessed August 21, 2025, https://civitai.com/articles/17883/multiple-characters-bounty-results
[15] extrafuzzy, "How I made over $1000 in 3 months selling LoRAs", Civitai, published October 22, 2023, accessed August 21, 2025, https://civitai.com/articles/2684/how-i-made-over-dollar1000-in-3-months-selling-loras.